Accelerate - The Science of Lean Software and Devops
Author :: Kevin Vecmanis
A review of key concepts I learned in the book Accelerate: The Science of Lean Software and Devops
Table of Contents
- Introduction
- Key Capabilities
- Westrum Organizational Culture
- Chapter 1 - Accelerate
- Chapter 2 - Measuring Performance
- Chapter 3 - Measuring and Changing Culture
- Chapter 4 - Technical Practices
- Chapter 5 - Architecture
- Chapter 6 - Integrating Infosec into the delivery process
- Chapter 7 - Management Practices for Software
- Chapter 8 - Product Development
- Chapter 9 - Making work sustainable
- Leaders, Managers, and Transformational Leadership
Introduction
The authors of Accelerate propose 24 key capabilities that drive improvements in software delivery performance. The capabilities are broken down into 5 categories, and the italics beside each capability are my own understanding and explanation of each. The rest of the review is a chapter-by-chapter summary of key concepts and how those concepts tie back in to these 24 key capabilities.
The overarching theme of this book is that software teams that drive continuous improvement around the 24 key capabilities were shown to be incredibly high performing engineering teams.
Key Capabilities
Continuous Delivery
- Version Control - Are all production artifacts being version controlled in some way.
- Deployment Automation - Are deployments between environments, especially to production, entirely automated.
- Continuous Integration - Code is regularly checked in and triggers a set of automated test to discover regressions which can be fixed immediately.
- Trunk-based Development - Few branches in a repository, which have short lives (less than a day) before being merged into master.
- Test Automation - Test suites are automated and run continuously through the development process. Tests are effective and find real failures and only pass releaseable code.
- Test Data Management - Do we keep and maintain adequate data to run unit tests and integration tests in any environment.
Architecture
- Leverages loosely coupled architecture - How much is the engineering culture focused around loose coupling.
- Empowered teams - Are teams able to choose their own tools, influence design decisions, and propose units of work.
Product and Process
- Customer Feedback - Does customer feedback get integrated back into the design and software delivery process
- Value Stream - Are engineers on the team aware of where their work stands in the full product delivery cycle and do they understand the impact on the business.
- Working in small batches - Are units of work sized appropriately such that work can get delivered continuously (at least once a day)
- Team experimentation - Are teams able to experiment with new design features and architectures that they feel may benefit the business
Lean Management & Monitoring
- Lightweight change approval process - How hard is it to get a PR approved
- Monitoring - Do you leverage technology to monitor the usage of apps as well as the backend performance
- Proactive notification - Are teams automatically notified when there is an issue with their app in production
- WIP limits - A lean manufacturing concept, which in the software development context means are there checks and balances in place to alert when work is taking too long.
- Vizualizing workflow states - Is it easy for the team to visualize, in one spot, the workflow states of the team as well as their own.
Cultural
- Westrum orgnizational culture - See section on Ron Westrum below
- Supporting and encouraging learning - Does the organization view learning as a cost or an investment?
- Collaboration among teams - How effectively do teams collaborate across siloes and scope.
- Job satisfaction - Are employees mentally healthy at work, and is the work being assigned a suitable fit for their skill-level.
- Transformational leadership - How well is management taking the necessary steps to build the right environment around the engineers to set them up for success.
Westrum Organizational Culture
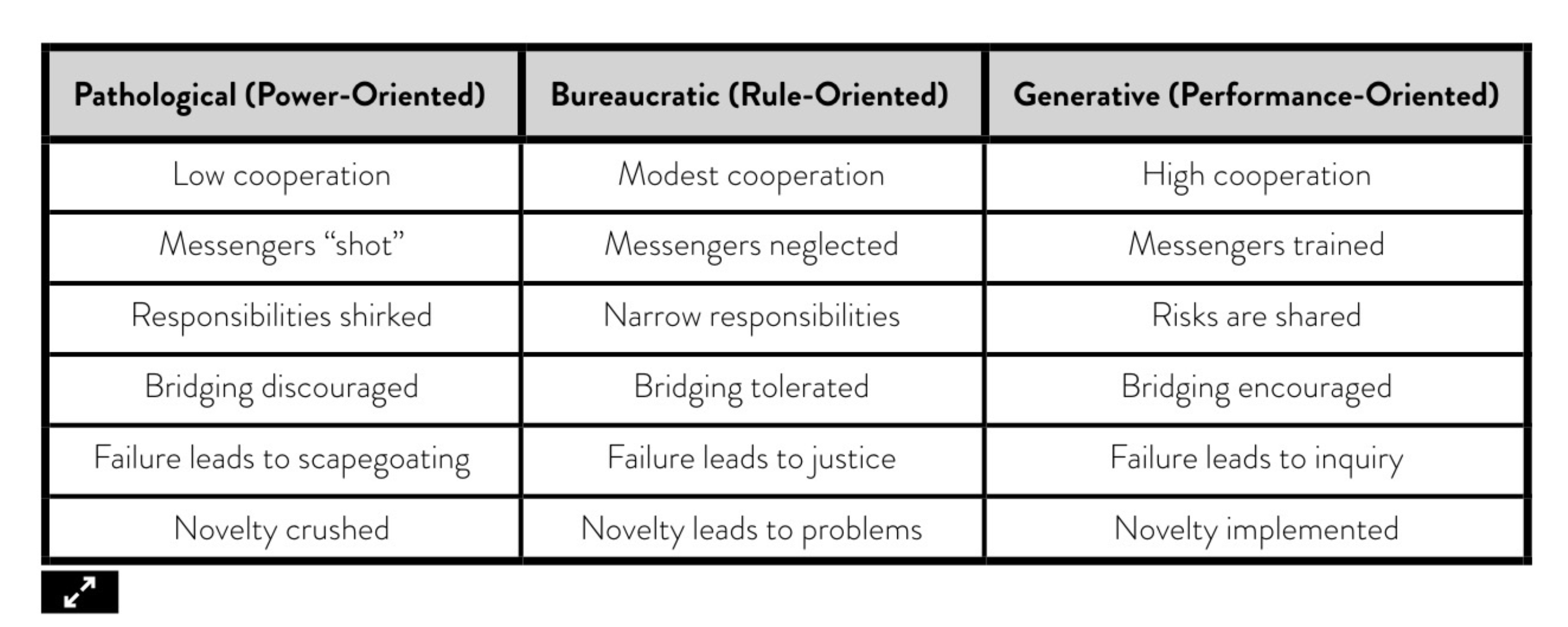
Ron Westrum was a sociologist who found that organizational culture was predictive of safety and performance outcomes in the healthcare industry. He developed a typology of organizational cultures that includes three types of organizations:
- Pathological (power-oriented): These organizations are characterized by low cooperation across groups and a culture of blame. Information is often withheld for personal gain.
- Bureaucratic (rule-oriented): Bureaucratic cultures are preoccupied with rules and positions, and responsibilities are compartmentalized by the department, with little concern for the overall mission of the organization.
- Generative (performance-oriented): The hallmarks of a generative organization are good information flow, high cooperation and trust, bridging between teams, and conscious inquiry.
The other good insight that Westrum had was that organizational culture predicts the information flows through an organization. He proposed three characteristics of good information:
- It provides answers to the questions that the receiver needs answered.
- It is timely.
- It is presented in such a way that it can be effectively used by the receiver.
Westrum was adament that good information flow is critical to the safe and effective operation of high-tempo and high-consequence environments, including technology organizations.
I find this interesting to think about alongside Conway’s law, which says that the software architecture at companies is often a reflection of the organizational structure
Chapter 1 - Accelerate
- The author opens the book by making the case that in the 21st century software is at the heart of accelerating the delivery of business value to customers.
- Technology leaders need to deliver software quickly and reliably to win in the market.
- The key to succesful change is measuing and understanding the right things with a focus on capabilities - not on maturity.
- The author breaks down business mindset into two buckets: maturity models and capability models
- Maturity models focus on helping an organization “arrive” at a mature state then declare themselves done - whereas in reality technology transformations should follow a continuous improvement paradigm.
- Capability models focus on helping an organization continually improve and progress, realizing that the business landscape is ever-changing.
- Capability models focus on key outcomes and the capabilities (levers) drive improvement in those outcomes - they are outcome based. It also allows teams to set improvement goals related to the capabilities of their team.
- The author argues with evidence that with a focus on capabilities teams can drive delivery tempo without sacrificing stability.
- Which capabilities to focus on will depend on the state of the team and the goals of the business/leadership team.
- The author cites research that says high performing teams in their studies, when compared to low performers, have:
- 46 times more frequent code deploys.
- 440 times faster lead time from commit to deploy.
- 170 times faster mean time to recover from downtime.
- 5 times lower change failure rate (1/5 as likely for a change to fail)
- High performers understand that you don’t have to trade speed for stability, or vice versa. By building quality in you get both.
Chapter 2 - Measuring Performance
- Measuring productivity in terms of lines of code has a long history in software. In reality, we would prefer a 10-line solution to a 1,000 line solution to a problem.
- Rewarding developers for writing lines of code leads to bloated software that incurs higher maintenance costs and higher cost of change.
- Ideally, you should reward developers for solving business problems with the minimum amount of code - and it’s even better if we can solve a problem without code at all, or by deleting code.
- Deleting code isn’t an ideal measure because at the extremes it also has drawbacks. Accomplishing a task in a single line of code that nobody can read is less desirable than writing a few lines of cofe that are easily understood, tested, and maintained.
- Using velocity as a productivity measure has several flaws:
- Velocity is a relative and team-dependent measure, not an absolute one. Teams typically have very different contexts which render their velocities incommensurable.
- When velocity is used as a productivity measure, teams are incentivized to game their velocity. Teams may inflate their estimates and focus on completing as many stories as possible at the expense of collaborating with other teams.
- One must be mindful when using utilization as a proxy for productivity as well:
- High utilization is only good up to a point.
- Once utilization gets too higher there is no spare capacity (or “slack”) to absorb unplanned work, changes to plan, or improvement work.
- Queue theory in math tells us that as utilization approaches 100%, lead times approach infinity.
- A successful measure of performance should have two key characteristics
- It should focus on a global outcome to ensure teams aren’t pitted against each other.
- It should focus on outcomes, not output: People shouldn’t be rewarded for putting out large volumes of busy work that don’t achieve organizational goals.
- The author and his team, factoring in these things, settled at four metrics:
- Delivery lead time,
- Deployment frequency,
- Time to restore service,
- Change fail rate
- The concept of “batch size” acts as in important metaphor in the author’s argument.
- Batch size is a central concept of the lean manufacturing paradigm - one of the keys to success of the Toyota production system.
- Reducing batch sizes reduces cycle times and variability in flow, accelerates feedback, reduces risk and overhead, improves efficiency, and increases motivation through tangible ownership.
- In sofware batch size is hard to measure and communicate across team contexts as there is no visible inventory (Like cars for Toyota).
- To address this the author settled on deployment frequency as a proxy for batch size since it’s easy to measure and typically has low variability.
- The author defines “deployment” as a software deployment to production or to an app store.
- Delivery lead times and deployment frequency are both measures of software delivery performance tempo.
- In most engineering systems, reliability is measured as time between failures.
- Software products and services are rapidly changing complex systems - failure is inevitable.
- The key question becomes: how quickly can service be restored?
Chapter 3 - Measuring and Changing Culture
- The author takes the paradigm that culture can exist at three levels in orgnizations: basic assumptions, values, and artifacts (Schein 1985)
- Basic assumptions are formed over time as members of a group or organization make sense of relationships, events, and activities. These interpretations are the least “visible” of the levels.
- Values are more “visible” to group members are these collective values or norms can be discussed and even debated by those who are aware of them.
- Values influence group interactions and activities by establishing social norms, which shape the actions of group members and provide contextual rules (Bansal 2003).
- Artifacts are the most visible cultural piece. These can include written mission statements or creeds, technology, formal procedures, or even heroes and rituals.
- In 2015 Google launched a huge study internally to see what made teams effective - they expected to find a combination of individual traits and skills that would be key ingredients of higher-performing teams.
- What they found instead was that “who is on a team” matters less than “how the team members interact, structure their work, and view their contributions”. (Google 2015).
- In other words, it all comes down to team dynamics.
- The author notes that how organizations deal with failures or accidents is particularly instructive. Pathological organizations look for a “throat to choke”. Investigations aim to find the person or persons “responsible” for the problem, and punish and blame them.
- The author notes that: in complex adaptive systems, accidents are almost never the fault of a single person who saw clearly what was going to happen and ran toward it or failed to act to prevent it. Rather, accidents typically emerge from a complex interplay of contributing factors.
- Failure in complex systems is, like other types of behaviour in such systems, “emergent” (Perrow 2011).
Chapter 4 - Technical Practices
- Continuous Delivery: A set of capabilities that enable us to get changes of all kinds – features, config changes, bug fixes, experiments – into production or in the hands of users safely, quickly, and sustainably. There are five key principles at the heart of continuous delivery:
- build quality in: Cease the dependence in manual inspection to achieve quality on a mass basis by building quality into the product up front
- Work in small batches: Organizations tend to plan work in big chunks. By splitting up work into much small chunks that deliver measurable business outcomes we get essential feedback on the work we are doing. Even though there is overhead involved with subdividing work, it reaps enormousrewards by allowing us to avoid work that delivers zero or negative value to organizations.
- Computers perform repetetive tasks; people solve problems: Automate as much as you can, especially with testing and deployments. Free up people to work on higher-level tasks.
- Relentlessly pursue continuous improvement: Never be satisfied with your current performance and always strive to get better.
- Everyone is responsible: Throughout, quality, and stability are all system-level objectives, and they can only be achieved by close collaboration between everyone involved in the software delivery process. A key objective for management in this respect is making the state of these system-level outcomes transparent.
- In order to implement continuous delivery, the author points to three critical capabilities:
- Comprehensive configuration management: It should be possible to provision our environments and build, test, and deploy software in a fully automated fashion purely from information stored in version control.
- Continuous integration (CI): Many dev teams are used to developing features on branches for days or even weeks. Integrating all the branches can require significant time and rework. Following the principle of working in small batches and building quality in, high-performing teams keep branches short-lived and integrate them into the trunk regularly.
- Continuous testing: Testing is not something that should only start once a features or release is “dev complete”. It should be done all the time throughout the development process. Automated unit and integration tests should be run against every commit to version control.
- “Unplanned work” and “re-work” are useful proxies for quality because they represent a failure to build quality into our products.
- Unplanned work is described as the difference between “paying attention to the low fuel warning light on an automobile versus running out of gas on the highway”.
- In the first case the organization can fix the problem in a planned and organized manner.
- In the second case they must fix the problem in a highly urgent manner, often requiring more resources than might otherwise be called for.
- John Seddon, creator of the Vanguard Method, emphasized the importance of reducing “failure demand” - demand for work caused by the failure to do the right thing the first time by improving the quality of service we provide.
Chapter 5 - Architecture
- In this chapter the author summarizes his research on the impact of architectural decisions and constraints on delivery performance.
- The author makes the argument that loose coupling is a key ingredient in any good architectural pattern.
- Loose coupling is what enables teams to easily test and deploy individual components or services even as the organization and the number of systems within it grow.
- In the author’s surveys they found that the following two statements were more likely to come from high-performing teams:
- We can do most of our testing without requiring an integrated environment.
- We can and do deploy or release our application independently of other applications/services it depends on.
- Testability and Deployability are the two primary architectural characteristics that enable high performance.
- In the author’s 2017 analysis the biggest contributor to continuous delivery is whether teams can:
- Make large-scale changes to the design of their system without the permission of somebody outside the team.
- Make large-scale changes to the design of their system without depending on other teams to make changes in their systems or creating significant work for other teams.
- Complete their work without communicating and coordinating with people outside their team.
- Deploy and release their product or service on demand, regardless of other services it depends on.
- Do most of their testing on demand, without requiring an integrated test environment.
- Perform deployments during normal business hours with negligible downtime.
- Conway’s Law states that “organizations which design systems are constrained to produce designs which are copies of the communication structures of these organizations” (Conway 1968).
- The author presents the idea of the “inverse Conway Maneuver” which states that “organizations should evolve their team and organizational structure to achieve the desired architectural structure”.
- The goal of your architecture is to support the ability of teams to get their work done without requiring high-bandwidth communication between teams.
A Loosely Coupled Architecture Enables Scaling
- The author makes the argument that if we achieve a loosely coupled, well-encapsulated architecture with an organizational structure to match, two import things happen:
- First, we can achieve better delivery performance, increasing both tempo and stability while reducing burnout and the pain of deployment.
- Second, we can substantially grow the size of our engineering organization and increase productivity linearly - or better than linearly - as we do so.
- The author challenges the popular belief when adding developers to a team overall productivity will increase but individual developer productivity will decrease. He states that in their study, high-performing teams were able to increase developer productivity (as measured by number of deploys per day per developer) non-linearly as team size grew:
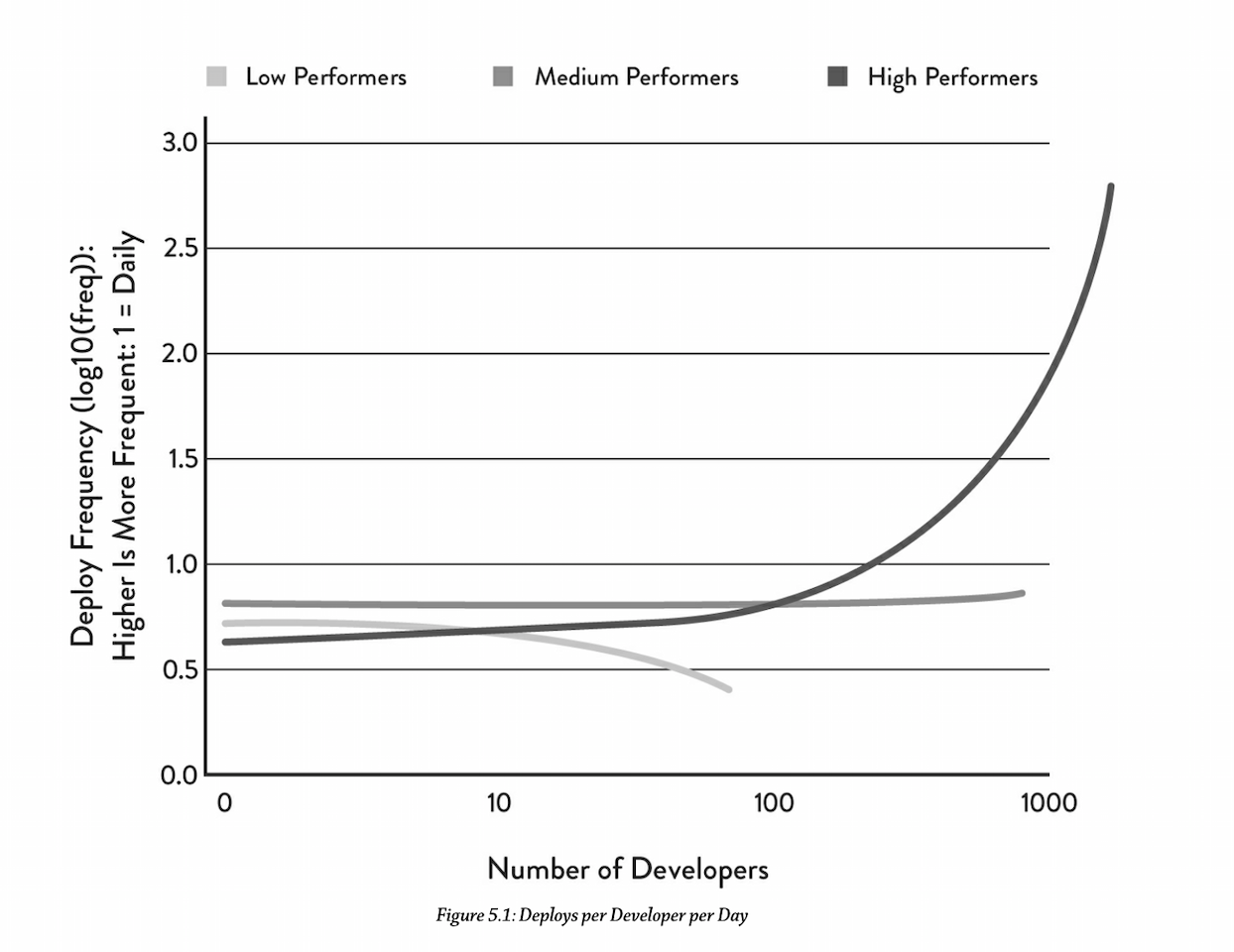
As the number of developers increases, the author found:
- Low performers deployed with decreasing frequency
- Medium performers deployed at a constant frequency
- High performers deployed at a significantly increasing frequency.
Allow Teams to Choose Their Own Tools
- It’s common for organizations to have standardized tools and frameworks. This typicall has the following benefits:
- Reducing the complexity of the environment
- Ensuring the necessary skills are in place the manage the technology through its lifecycle.
- Increasing purchasing power with vendors
- Ensuring all technologies are correctly licensed for liability reasons.
- The author argues there’s a downside to this lack of flexibility: it prevents teams from choosing technologies that will be most suitable for their particular needs, and from experimenting with new approaches and paradigms to solve their problems.
- The author acknowledges that there’s a place for standardization - particularly around architecture and the configuration of infrastructure.
- Architecture should focus on engineers and outcomes, not tools or technologies
- What tools or technologies you use is irrelevant if the people who must use them hate using them, or if they don’t achieve the outcomes and enable the behaviours we care about.
Chapter 6 - Integrating Infosec into the delivery process
- The author argues that information security is often understaffed at organizations - citing ratios of 1 infosec per 10 infrastructure people per 100 developers.
- High performing software companies “shift left” on security and integrate it into the development process and educate teams on it, rather than having a central team that gets involved further downstream in the dev process.
- What does shifting left entail?
- Security reviews are conducted for all major features, and performed in such a way that is doesn’t slow down the dev process.
- Information security should be integrated into the entire software delivery cycle.
- Make it easier for developers to do the right thing: pre-approved libraries, packages, toolchains, and processes made available for developers.
- Educating developers on standard security practices and risks - like the OWASP Top 10
- High-performing companies in the author’s study spent 50% less time remediating security issues than low performers.
Chapter 7 - Management Practices for Software
- Most of the best-in-class management practices for software engineering have been derived from the lean manufacturing movement pioneered by Toyota.
- The author maps three lean principles to software engineering key capabilities:
- Limiting work-in-progress (WIP), and using these limits to drive process improvement and increase throughput.
- Creating and maintaining visual displays showing key quality and productivity metrics, and making these displays visible to both engineers and leaders.
- Using data from application performance and infrastructure monitoring tools to make business decisions on a daily basis.
- WIP limits are not effective if there’s not a feedback loop in place that leads to improvements that increase flow.
About PR Review Processes
- This author and his team conducted a study on the impact that change approval processes have on software delivery performance. They categorized the types of approval processes into four buckets:
- All production changes must be approved by an external boddy (such as a manager or Change Approcal Board (CAB)).
- Only high-risk changes, such as database changes, require approval.
- We rely on peer reviews to manage changes.
- We have no change approval process.
- The author’s team found that approval for only high-risk changes (process 2) was not correlated with software delivery performance.
- Teams that reported no approval process or user peer review achieved higher software delivery performance.
- Teams that used process 1 achieved the lowest performance.
- Interestingly, process 1 was negative correlated with lead time, deployment frequency, and restore time, and had no correlation with change fail rate.
- In other words, the study produced no evidence to suggest external approcal bodies simply don’t work to increase stability on production systems, but they definitely slow things down.
- The author’s recommendation from the study is to use a lightweight peer review process, combined with an automated deployment pipeline to detect and reject bad changes.
Chapter 8 - Product Development
- In the author’s study, it showed that the following four key capabilities were statistically significant in predicting higher software delivery performance and organizational performance:
- The extent to which teams slice up products and features into small batches that can be completed in less than a week and released frequently, including the use of MVPs.
- Whether teams have a good understanding of the flow of work from the business all the way through to the customers, and whether they have visibility into this flow, including the status of products and features.
- Weather the organizations actively and regularly seek customer feedback and incorporate this feedback into the design of their products.
- Whether dev teams have the authority to create and change specifications as part of the dev process without requiring approval.
Chapter 9 - Making work sustainable
- In the author’s opinion, the number one factor that makes work unsustainable for developers is deployment pain.
- The fear and anxiety engineers and technical staff feel when they push code to production can tell us a lot about the team’s software delivery performance.
- The author’s research shows that improving key technical capabilities reduces deployment pain. Teams that do the following decrease their deployment pain:
- implement comprehensive test and deployment automation,
- use continuous integration, including trunk-based development,
- shift left on security,
- effectively manage test data,
- use loosely coupled architecture,
- work independently,
- user version control for everything
- In order to reduce deployment pain where it exists, we should:
- Build systems that are designed to be deployed easily into multiple environment, can detect and tolerate failures in their environments, and have various components of the system updated indepedently.
- Ensure that the state of the production systems can be reproduced (with the exception of production data) in an automated fashion from information in version control.
- Build intelligence into the application and the platform so that the deployment process can be as simple as possible.
Burnout
- Burnout is physical, mental, or emptional exhaustion caused by overwork or stress.
- Burnout can make the things we once loved about our work and life seem insignificant and dull. It often manifests as a feeling of helplessness, and is correlated with pathological cultures and unproductive, wasteful work.
- In extreme cases, burnout can lead to family issues, severe clinical depression, and even suicide.
- Job stress also affects employers, costing the US economy $300 Billion per year in sick-time, disability, and excessive job turnover (Maslach 2014).
- Effective devops practices can help reduce burnout risks.
Managers that want to avert employee burnout should concentrate their attention and effort on:
- Fostering a respectful, supportive work environment that emphasized learning from failures rather than blaming.
- Communicating a strong sense of purpose.
- Investing in employee development.
- Asking employees what is preventing them from achieving their objectives and then fixing those things.
- Giving employees time, space, and resources to experiment and learn.
Common problems that can lead to burnout
- Work overload: job demands exceed human limits.
- Lack of control: inability to influence desisions that affect your job.
- Insufficient rewards: insufficient financial, institutional, or social rewards.
- Breakdown of community: unsupportive workplace environment.
- Absence of fairness: lack of fairness in decision-making processes.
- Value conflicts: mismatch in organizational values and the individual’s values.
- The author found that organizations try to fix the person and ignore the work environment, even though research shows that fixing the environment has a higher likelihood of success.
Leaders, Managers and Transformational Leadership
- In the author’s opinion, the role of leadership in technology transformation has been one of the more overlooked topics in devops, despite it being essential for:
- Establishing and supporting generative and high-trust cultural norms.
- Creating technologies that enable developer productivity, reducing code deployment lead times and supporting more reliable infrastructures.
- Supporting team experimentation and innovation, and creating and implementing better products faster
- Working across organizational silos to achieve strategic alignment.
- The author uses the Rafferty and Griffin (2004) model of transformational leadership that has five characteristics:
- Vision: Has a clear understanding of where the organization is going.
- Inspirational communication: Communicates in a way that inspires and motivates, even in uncertain or changing environments.
- Intellectual stimulation: Challenges followers to think about problems in new ways.
- Supportive leadership: Demonstrates care and consideration of followers’ personal needs and feelings.
- Personal recognition: Praises and acknowledges achievement of goals and improvements in work quality; personally compliments others then they do outstanding work.