Building a Brain - Distributing Machine Learning Models in NoSQL
Author :: Kevin Vecmanis
In this post I walk through an architecture model for building better operational intelligence into VanAurum by distributing and accessing many machine learning models in MongoDB, a popular open source NoSQL database framework.
In this article you will learn:
- Terminology differences between NoSQL and SQL
- Pulling structured SQL data using SQLAlchemy
- Training a machine learning model using MLAutomator
- Storing the model in MongoDB with all the details required to load and make predictions
- How to load a model from MongoDB
Table of Contents
- Introduction
- Thoughts on System architecture
- Structrure of the Distributed Model Cluster (Brain)
- Structure of VanAurum’s model cluster
- Pulling structured data from PostGreSQL
- Prepare data for machine learning algorithms
- Training the models with MLAutomator
- Saving the Model and Meta Data to MongoDB
- Loading the Model and Meta Data from MongoDB
- List of helper functions
Introduction
Operational Intelligence (OI) is a term that describes one of the more immediate and practical use cases of machine learning and AI in business. As machine learning gets more and more capable the possibilities for OI are going to grow with it.
Wikipedia has this to say about OI:
The purpose of OI is to monitor business activities and identify and detect situations relating to inefficiencies, opportunities, and threats and provide operational solutions. Some definitions define operational intelligence as an event-centric approach to delivering information that empowers people to make better decisions, based on complete and actual information.
You can define operational intelligence however you like, but I regard it as just varying degrees of analysis automation. Questions that at one time would need to be answered manually by a person are now coming under the purview of OI. Consider the following questions:
- How does my customer purchasing behaviour change on days that it’s rainy ?
- Who are my customers most likely to convert to a premium service given that they already purchase the standard service ?
- What 3 asset classes have the highest apriori probability of rising over the next 2 months ?
These are all questions that require you to source data, build a model, and project that model forward into the future. There is real leg-work required for people to do this, so why should we expect anything different from an AI system delivering OI insights?
With any intelligent or semi-intelligent system, I think it’s unreasonable to expect it to know something until it knows it.
Consider yourself and everything that you currently know. You’re reading the words on this page without any thought or consideration for the individual letters in the words. You’re likely not even conciously thinking about individual words - you’re just reading, and the words are stimulating “concepts” in your mind that your brain is stringing together from past “models” it has learned from.
At one point in your life you didn’t know what the letter A was. A capital A has three lines in it, and at one point you didn’t even know what a line was. These are all things we learn to identify over time, through exposure and repetition. Learning is the process of piling one abstract concept on top of another:
- Lines make letters
- Letters make up words
- Words make up sentences
- Sentences express concepts
- The concept in a sentence can elicit even higher level concepts - humour, irony, paradox.
- Sentences can comprise paragraphs, pages, and books that can represent an entire life’s worth of abstraction and ideas.
The message here is that you don’t know something until you do. So if we’re going to build an operational intelligence framework, why should the process be any different?
In the rest of this post I’m going to walk through the implementation of an OI system I’m building for VanAurum. The code here is as robust as it needs to be for demonstration purposes, but no more. I hope you enjoy it.
Thoughts on System Architecture
To build an operational intelligence framework in the manner I’m going to discuss, it requires a solid data infrastructure and foundation. In my own opinion, 90-95% of the time spent designing any holisitc machine learning system should be spent thinking through, designing, and building the data infrastructure. The importance of it can’t be understated - it’s like the foundation in a skyscraper.
It also requires extensive engagement with the business professionals in your organization. Regardless of how good your data infrastructure is, if you’re not collecting the data that’s needed to make smart business decisions or add customer value it’s all for nothing.
The framework we’re looking at here is as follows:
- Extract data from structured data sources: In this case I’m pulling data from a PostGreSQL database hosted on Heroku. This database contains all the structured data VanAurum uses to generate market analysis.
- Transforming the data into a format applicable to each learning instance, which I’ll describe below.
- Fit an optimal machine learning pipeline to the data.
- Store the pipeline in a NoSQL database with all of the meta data required to access the same database the model was trained on (so that it can perform predictions in the future on an updated version of the database table).
- Retrieving the models and their meta data so that they can be used for OI.
So what kind of stuff do I want to do with this OI layer? In particular, I want VanAurum to be able to answer questions like:
- What is the probability that Gold prices will be higher in 5 days? 20 days? 161 days?
- What five assets have the highest probability of trading lower in one month?
How the models are trained, and the extent to which this data can be relied on in relatively non-deterministic systems like financial markets is a topic for another article.
Hypothetically speaking, these questions would be fairly easy to answer if you had a database table of probabilities with a schema roughly like this:
TABLE : Probabilities
SCHEMA:
(PRIMARY_KEY) AssetName: TYPE char
1_Day_Probability: TYPE float
2_Day_Probability: TYPE float
3_Day_Probability: TYPE float
4_Day_Probability: TYPE float
.
.
.
.
N_Day_Probability: TYPE float
You could answer the first question like:
SELECT 5_Day_Probability, 20_Day_Probability, 161_Day_Probability
FROM Probabilities
WHERE (AssetName = "GOLD")
And you could answer the second question like:
SELECT TOP 5 AssetName, 21_Day_Probability
FROM Probabilities
ORDER BY 21_Day_Probability ASC
-- Note: VanAurum predicts probability of a rise. Probability of fall = (1 - probability of rise)
Simple enough, right? The goal of the OI system is to make the intelligent insights easy enough to access that business professionals using standard analytics sofware (like Mode or MetaBase) can get the intelligent insights from the user interface. This type of simple query could easily be handled by off-the-shelf OI software - and this is our goal.
Lots of business professional don’t have the time, desire, or knowledge to perform complex SQL queries - and this is the value that OI analytics software can deliver. But imagine our Probabilities table didn’t exist? Answering these questions en-masse would become difficult.
This is where our distributed model cluster (brain) comes into play. The intention of this cluster of models is to push value-added information to a structured dataset with a schema that makes it more easily accessible by analytics software. With a robust underlying data-ingestion framework, a cluster of models can be built on top of it to facilitate any type of OI that the data permits.
Structrure of the Distributed Model Cluster (Brain)
NoSQL databases lend themselves well to storing machine learning models. Some of the reasons are:
- You don’t need a predefined schema - not a deal breaker here, but if you don’t need one why make one?
- Very well suited to hierarchical data storage - you’ll see why this benefts us when you see VanAurum’s structure below.
- Horiztonally scalable - which means you can easily cluster NoSQL databases. This is a huge benefit for accumulating machine learning models because you want to be able to quickly and easily store and access models. It wouldn’t be much of a “brain” if you couldn’t!
Quick note: Going forward, when I mention the following NoSQL terms you can think of the SQL equivalent:
- Collection = Table
- Document = Row/Record
All of the other shortcomings of NoSQL databases - like the fact that it doesn’t support complex relations and queries - aren’t really a design concern for us. Why? Because all we want is a quick way to store and load machine learning models in a hierarchical format. Each model will be explicitly called when it needs to be, and there are no relationships between any of the models. We also want it horizontally scalable so that we can add thousands of models without significant degradation in retrieval time. If this isn’t an application for NoSQL, I’m not sure what is!
Structure of VanAurum’s Model Cluster
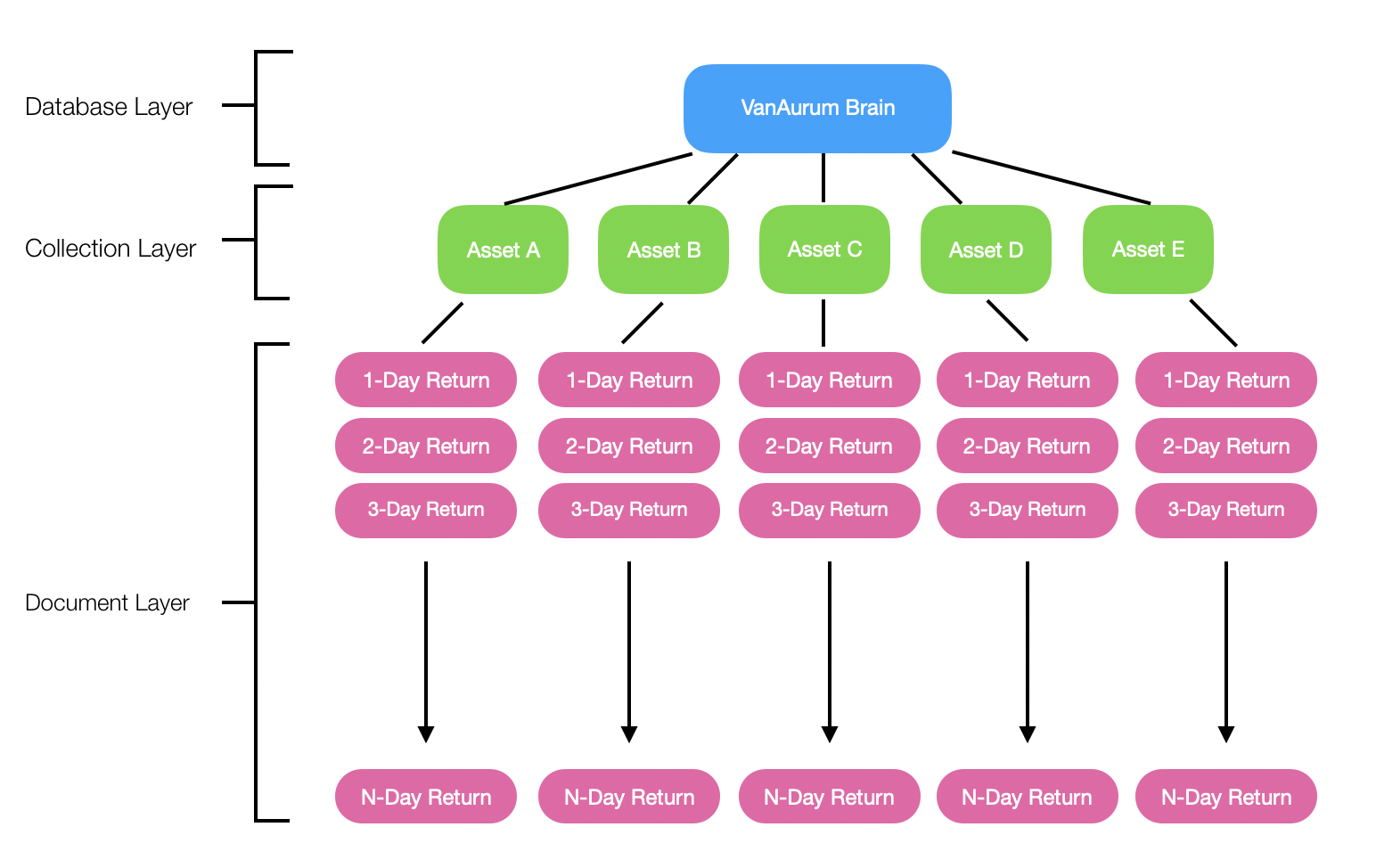
You see the hierarchical and horiztonal nature of this model cluster - this will make the cluster extremely scalable if we use the right cloud technology (Like MongoDB on Heroku or DynamoDB on AWS).
What we want to do is train models on predicting a comprehensive variety of N-day return periods for whatever asset class we want to make predictions on. Assets could be things like: Gold, Copper, S&P 500 index, Bitcoin, ratios, or individual stocks.
In this article I’m going to walk through a demonstration for one asset class - Gold - and one return period - 25 days.
I’m using the python library for MongoDB - PyMongo. Let’s dive into the code!
Pulling Structured Data From PostGreSQL
The following function pulls data from a PostGres database hosted on Heroku, transforms it into a training data set with a single return period as a target.
Important: There are helper functions used by some of the following methods. All the helper functions are included at the end of this article: List of helper functions. I’ll include a # Helper tag beside each method that is a helper. I wanted to stick to the point here and not clutter the code section too much.
def create_training_data(asset, return_period):
'''Ingests a table from remote database, prepares it with a single training target, and saves as a
CSV file.
Parameters:
asset : string
The asset class table to pull from VanAurum's database. (i.e, 'GOLD')
return_period : int
The return period that the model will train itself on (i.e, 25-Day Returns)
'''
data = table_to_df(asset) # Helper
filter_returns(data, return_period) # Helper
bin_returns(data, return_period) # Helper
drop_additional(data) # Helper
save_to_csv(data, asset) # Helper
print('Succesfully imported and saved '+asset)
return
The next thing we want to to is load this .csv file and split it into readable feature/target ndarray types that are readable by our machine learning algorithms.
Prepare Data for Machine Learning Algorithms
Note that in this method we return not only X and Y training/target data, we also return features. We’re going to use this in our NoSQL document entry so that when we retrieve models we know what columns from our base data table were used in the training process.
def data_prep(filename = None, target_columns = 1, ignore_columns = None):
'''A utility method for preparing training and target data from a csv file.
Parameters:
filename : string
The file name of the dataset to be imported. This function assumes the
dataset resides in os.environ.get('TRAINING_DATA_DIRECTORY')
target_columns : int, optional, default=1
The number of target columns there (in case it might be one-hot encoded, for example).
Method assumes that target columns reside at the end of the dataframe. The default value takes
the last column as the target.
ignore_columns : list, optional, default = None
A list of column names or indices that you want dropped or ignored during preparation.
These columns will not be included in the output.
Returns:
x_train : ndarray
Training data for the model.
y_train : ndarray
Target data for the model.
Raises:
AssertionError
- If TRAINING_DATA_DIRECTORY is not set as environment variable.
- If no file exists at the assembled file pathway.
'''
# Check that a directory is set in the environment
assert(os.environ.get('TRAINING_DATA_DIRECTORY') not None, 'TRAINING_DATA_DIRECTORY not set in environment')
data_directory = os.environ.get('TRAINING_DATA_DIRECTORY')
#Check if the provided path is a file
path = data_directory + filename
assert(os.path.isfile(path), 'The specified file does not exist: '+path)
#Load data from csv file.
training_data = pd.read_csv(data_directory+filename, header=0)
# If user specifies additional columns to drop, do that now.
if ignore_columns:
training_data = training_data.drop(ignore_columns, axis=1)
# Transform the loaded CSV data into numpy arrays
columns = list(training_data)
features = columns[:-1] # Features are all columns except the last
feature_data = training_data[features]
target_data = training_data[columns[-target_columns:]] # Target data is the last column
x_train = feature_data.values
y_train = target_data.values
return x_train, y_train, features
Training the Model With MLAutomator
Here we’re going to do a few things:
- Declare several variables that get saved in the MongoDB document along with each model.
asset: The asset table to pull from our PostGres database.sources: VanAurum’s assets are split into their own database tables. If joins are required to reconstruct the training dataset, the complete list of tables are listed here. In this case we’re only using a single table.return_period: Used to create our target column. Also gets saved to MongoDB as an identifiier for the model (see diagram shown previously)
- Create the training dataset using our method
create_training_dataset() - Generate
XandYtraining data, along withfeatureswhich gets saved as meta data for our MongoDB model so that the training table can be reconstructed. - Train our model using
MLAutomator- this is my open source library for fast model selection using bayesian optimization. See it on Github here: MLAutomator
import pickle
from mlautomator.mlautomator import MLAutomator
asset = 'GOLD_D'
sources = [asset]
return_period = 25
create_training_data(asset, return_period)
try:
x, y, features = data_prep(asset + '.csv', 1)
except AssertionError as error:
print(error)
print('Exiting data preparation function')
# 'x' is a local variable if data_prep() finished successfully...
if x in locals():
# Fit optimal pipeline using MLAutomator
automator = MLAutomator(x, y, score_metric = 'neg_log_loss')
automator.find_best_algorithm()
automator.fit_best_pipeline()
# Continued below....
Saving the Model and Meta Data to MongoDB
As mentioned previously, there are a few bread crumbs we want to save as meta data so that our models are going to be useful in the future.
- We want to be able to reconstruct the data the model was trained on so that we can make predictions on the same data in the future.
- MLAutomator saves a complete pipeline (pre-processing, feature selection, and training), so we don’t need to worry about those here.
- We do need to save:
- The schema from the original structured data that were used -
features model_name, so that we can reference the model later.- A list of all the source tables used to build the data
- The connection string to access the database that the training data was pulled from. Why? Because new data we want to make predictions on is going to appear here in the future.
- The schema from the original structured data that were used -
# Standard Python Library Imports
import datetime
# 3rd Party Imports
from pymongo import MongoClient
def save_model_to_brain(model, client_str, db, collection, model_name, features, source_tables, source_conn):
'''Method for saving trained machine learning model and meta data to MongoDB.
Parameters:
model : object
A fitted machine learning model or pipeline.
client_str : string
Connection parameters for the MongoClient.
db : string
Name of MongoDB we're accessing collections and documents from.
collection : string
The name of the collection in db that we want to write a new document to.
model_name : string
The name by which this model will be referenced in the future.
features : list
The list of column names from the original structured data that were used to train this model/pipeline.
source_tables : list
The list of all tables from structured database used to construct the original raw training data.
source_conn : string
The connection string for the database.
Returns:
results : dict
Results from the MondoDB insertion operation.
'''
created_on = datetime.datetime.now().strftime("%m/%d/%Y, %H:%M:%S")
# Serialize machine learning model/pipeline
pickled_model = pickle.dumps(model)
# Connect to MongoDB
client = MongoClient(client_str)
database = client[db]
# Create the collection if it does not exit
if not collection in database.list_collection_names():
database.create_collection(asset)
target_collection = database[collection]
# Build document to insert and insert it
insertion_job = target_collection.insert_one({
model_name: pickled_model,
'name': model_name,
'created_on': created_on, # So we know if this model is stale
'schema': features,
'source_tables': source_tables,
'source_connection': source_conn, # probably want to encrypt this before insertion.
'description' : 'Model to predict '+model_name+' for '+collection,
})
results = {
'inserted_id': insertion_job.inserted_id,
'model_name': model_name,
'created_on': created_on,
}
print('succesfully saved model')
return results
Loading the Model and Meta Data from MongoDB
def load_model_from_brain(model_name, client_str, db, collection):
'''Method for loading saved model and metadata from MongoDB
Parameters:
model_name : string
Name of document to load from collection.
client_str : string
Connection string for MongoClient.
db : string
Name of MongoDB we're accessing collections and documents from.
collection : string
Name of collection that our model document is stored in.
Returns:
model/pipeline : object
A 'de-pickled' model/pipeline from which you can make predictions on new data.
bread_crumbs : dict
A dictionary of information necessary to reconstruct new prediction data.
Raises:
Exception
If the specified collection isn't present in the database.
'''
json_data = {}
# Connect to Mongo database
client = MongoClient(client_str)
database = client[db]
# Raise an exception if the provided collection does not exist
if not collection in database.list_collection_names():
raise Exception ('The specified collection does not exist yet. The collection was: {}'.format(collection))
target_collection = database[collection]
# Retrieve model document using model_name
data = target_collection.find({'name': model_name})
# Store returned data as dict
for i in data:
json_data = i
pickled_model = json_data[model_name]
# Build 'bread crumb' dictionary so that prediction data can be built
bread_crumbs = {
'schema': json_data['schema'],
'source_tables': json_data['source_tables'],
'source_connection': json_data['source_connection'],
}
return pickle.loads(pickled_model), bread_crumbs
Tying These Methods Together
To tie these last few code segments together, here’s what that complete process looks like when we add save_model_to_brain() and load_model_from_brain()
# Continued from above...
details = save_model_to_brain(
model = automator.best_pipeline,
client_str = 'mongodb://localhost:27017/', # Or wherever your MongoDB is located...
db = 'vanaurum_brain',
collection = asset,
model_name = 'RETURNS' + str(return_period),
features = features,
source_tables = sources,
source_conn = os.environ.get('DATABASE_URL'),
)
model, data_specs = load_model_from_brain(
model_name = 'RETURNS25',
client_str = 'mongodb://localhost:27017/',
db = 'vanaurum_brain',
collection = asset,
)
Checkpoint - What have we done so far?
So we have basically built this from our original cluster structure:
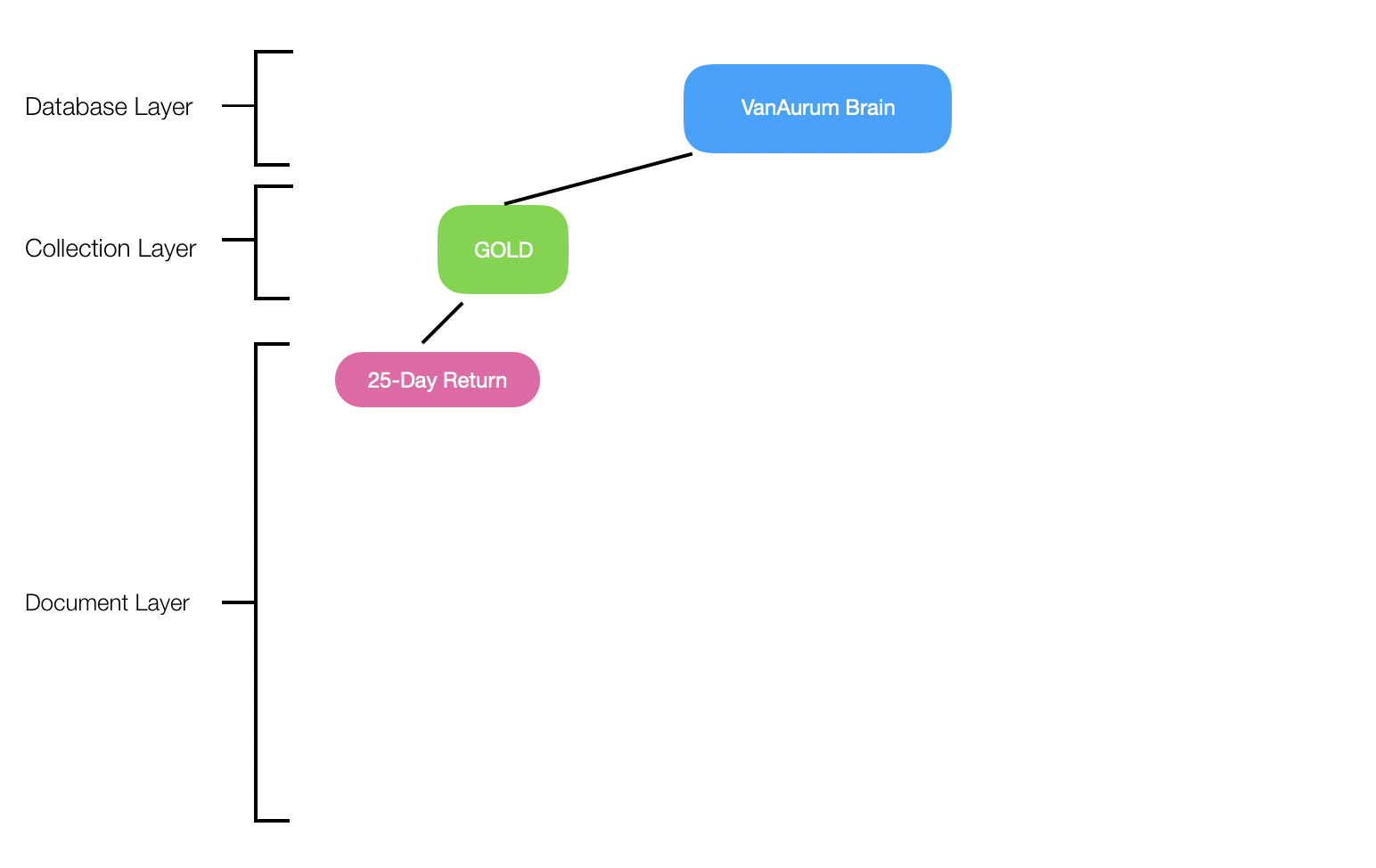
- We have one collection,
GOLD, and one document,RETURNS25. - We’ve built the methods necessary to:
- Pull structured data
- Build training data sets
- Train models
- Save models into our cluster
- Load models from our cluster
Filling in the rest of our cluster is just a matter of looping through the asset tables and desired return periods and executing these methods.
Looping back to our original objective…
What was the point of this again? Well we want to break down as many barriers as possible between business professionals and intelligent data insights. Operational Intelligence systems don’t become intelligent on their own - they require robust data infrastucture, purposeful data collection, and a streamlined process for identifying areas where OI clusters like this should be built.
A lot can be accomplished from an analytics perspective just by having the right data structured in the right schema - Machine learning doesn’t need to be applied everywhere. For some insights, you do need machine learning - and if you need to cover a wide breadth of questions, NoSQL clusters like this are one way to build it at scale!
I hope you enjoyed this post. Below this are the helper methods and additional libraries that were used in the main methods above. Feel free to check them out.
Helper Functions
Required libraries:
# Standard Python Library Imports
import pandas as pd
import os
import numpy as np
import datetime
import time
#3rd Party Imports
from sqlalchemy import create_engine # To generate queries to PostGres database.Methods
def query_to_df(query):
'''Queries data from table and stores as pandas Dataframe object.
'''
# PostGres connections string stored in environment variables as DATABASE_URL
engine = create_engine(os.environ.get('DATABASE_URL'))
df = pd.read_sql_query(query, engine)
return df
def table_to_df(tag):
'''Pulls all data for a specific asset. (i.e, 'GOLD').
'''
query = f'SELECT * FROM "{tag}"'
df = query_to_df(query)
return df
def bin_returns(dataframe, return_period):
'''Encodes returns as either 1 (Up) or 0 (Down)
'''
dataframe['BINARY'+str(return_period)] = np.where(dataframe['RETURNS'+str(return_period)] >= 0, 1, 0)
dataframe.drop(columns = ['RETURNS'+str(return_period)],inplace = True)
def filter_returns(dataframe, keep_return):
'''VanAurum's standard asset schema has a range of returns pre-calculated. This method drops
all but the desired return period.
'''
returns = [x for x in list(dataframe) if ('RETURNS' in x and x!= 'RETURNS' +str(keep_return))]
dataframe.drop(columns = returns, inplace = True)
return
def drop_additional(dataframe):
'''Drops other data not needed for model training: Date, Close, Open, High, Low, Volume.
'''
drop_list = ['Date', 'Open', 'High', 'Low', 'Close', 'Volume']
for column in drop_list:
try:
dataframe.drop(columns = [column], inplace = True)
except:
continue
def save_to_csv(table, name):
'''Saves the training data to a .csv file in the directory specified by
the environment variable 'TRAINING_DATA_DIRECTORY'
'''
directory = os.environ.get('TRAINING_DATA_DIRECTORY') + name +'.csv'
table.dropna(inplace = True)
table.to_csv(directory, index = False)