Stream Data to Google BigQuery with Apache Beam
Author :: Kevin Vecmanis
In this post I walk through the process of handling unbounded streaming data using Apache Beam, and pushing it to Google BigQuery as a data warehouse.
In this article you will learn:
- How to stream multi-attribute data to Google Pubsub
- How to create an Apache Beam pipeline to process streaming multi-attribute data
- The structure around Apache Beam pipeline syntax in Python
- How to output the data from Apache Beam to Google BigQuery
Table of Contents
- Introduction
- Creating the mock stock price stream
- Building the Apache Beam data pipeline
- Ingesting Data From Difference Sources
- Diving Deeper into Apache Beam
- Summary
Introduction
Data engineers deal with two main types of data processing when they’re designing ETL pipelines: batch and stream. The key distinction is that batch processing is done on data sources that are fixed and finite in size (importing data from a .csv file, for example), whereas streams are unbounded data. This could be something like temperature data from an IoT sensor that sends an updated value every 5 seconds and never ends.
In this post I’m going to stream mock second-by-second stock data using Apache Beam and Google Data Flow as the data runner. Apache Beam is a nice SDK, but the methodology and syntax takes some getting used to. I’m going to do the best I can to explain this if you’re unfamiliar.
The output of our data pipeline is going to dump into Google Big Query - a powerful data warehouse that facilitates all kinds of analysis. I hope you enjoy this!
Creating the Mock Stock Price Stream
To create our stock market price stream, I’ve created a simple class that creates a random-walk stock price by calling the __next__ method.
# Standard Python Library Imports
import numpy as np
import logging
# Initialize logger
logging.basicConfig(
level = logging.INFO,
format = '%(message)s',
)
log = logging.getLogger(__name__)
class StockGenerator:
'''Generates random-walk stock value from a provided mu, sigma,
and starting stock value.
'''
def __init__(self, mu, sigma, starting_price = 100):
self.mu = mu
self.sigma = sigma
self.stock_value = starting_price
self.dist = np.random.normal(mu, sigma, 1000)
def __next__(self):
random_return = np.random.choice(self.dist, 1)
self.stock_value = self.stock_value * random_return[0]
log.info('New stock value: %s', self.stock_value)
return self.stock_valueCalling the __next__ method will produce a new value of the stock based on the prior value that varies according to a distribution defined by a mu and sigma that you specify. The output looks like this:
New stock value: 100.0605626178124
New stock value: 100.16591843889884
New stock value: 100.28548431538503
New stock value: 100.24684703140774
New stock value: 100.47129110727234
New stock value: 100.71474859108991
New stock value: 100.84707200326982
New stock value: 101.03516354077385
New stock value: 101.23282725242157
New stock value: 101.33349858811373
New stock value: 101.4227323808079
.
.
.
For this tutorial, what we want to do is run this stock price generator indefinitely in a loop and have it publish the stream to Google Pubsub. I’ve created the following module to do this, which can be run locally if you have the gcloud SDK installed, or from the cloud shell on Google Cloud Console.
#mock_stream.py
# Standar Python Library Imports
import time
import datetime
import json
import base64
# Local imports
from stock_generator.stock_generator import StockGenerator
# 3rd Party Imports
from google.cloud import pubsub
PROJECT = 'vanaurum'
TOPIC = 'stock-stream'
def pub_callback(message_future):
# When timeout is unspecified, the exception method waits indefinitely.
topic = 'projects/{}/topics/{}'.format(PROJECT, TOPIC)
if message_future.exception(timeout=30):
print('Publishing message on {} threw an Exception {}.'.format(
topic, message_future.exception()))
else:
print(message_future.result())
def main():
# Publishes the message 'Hello World'
publisher = pubsub.PublisherClient()
topic = 'projects/{}/topics/{}'.format(PROJECT, TOPIC)
stock_price = StockGenerator(mu = 1.001, sigma = 0.001, starting_price = 100)
while True:
# Pause for 1 second to mimic second-by-second data
time.sleep(1)
price = next(stock_price)
timestamp = str(datetime.datetime.utcnow()) # str to make json serializable
# Create the body of the message we want to publish in the stream
body = {
'stock_price': price,
'timestamp': timestamp,
}
# Dump to json and encode as string, as is required by Pubsub
str_body = json.dumps(body)
data = base64.urlsafe_b64encode(bytearray(str_body, 'utf8'))
message_future = publisher.publish(
topic,
data=data,
)
message_future.add_done_callback(pub_callback)
if __name__ == '__main__':
main()This module does the following:
- Creates an instance of
StockGeneratoras the variablestock_price. - In an indefinite loop:
- Pauses for 1 second to mimic second-by-second stock data.
- Gets a randomly generated stock value.
- Creates a timestamp.
- Packages these two entries in a dictionary.
- Dumps the dictionary to a JSON object.
- Encodes the JSON object.
- Publishes the encoded message to our pubsub topic
stock-stream.
This will run until we shut it off - which means it’s “unbounded”. The next thing we’re going to do is build out our Apache Beam data pipeline for processing this stream.
Building the Apache Beam Data Pipeline
I want to cover some introductory ground regarding the Python syntax for Apache Beam - the code that follows will make more sense if I do.
The Apache Beam website says this about the Apache Beam SDK:
Apache Beam is an open source, unified model for defining both batch and streaming data-parallel processing pipelines. Using one of the open source Beam SDKs, you build a program that defines the pipeline. The pipeline is then executed by one of Beam’s supported distributed processing back-ends, which include Apache Apex, Apache Flink, Apache Spark, and Google Cloud Dataflow.
Beam is particularly useful for Embarrassingly Parallel data processing tasks, in which the problem can be decomposed into many smaller bundles of data that can be processed independently and in parallel. You can also use Beam for Extract, Transform, and Load (ETL) tasks and pure data integration. These tasks are useful for moving data between different storage media and data sources, transforming data into a more desirable format, or loading data onto a new system.
In a nutshell, Apache Beam is a framework that allows you to:
- Get data from somewhere
- Do some things do it
- Dump it somewhere
In a fast, parallel way. Google Cloud Dataflow is a supported runner for Apache Beam jobs, and that’s how we’re going to run the job described in this tutorial. That being said, one of the nice things about Apache Beam is that it’s indifferent to the runner being used - you can swap out the runner for something else entirely just by changing a flag value. You’ll see this when we create our bash script to run this pipeline job.
A common design pattern you’ll see with Apache Beam pipeline scripts is for the pipeline parameters (and other parameters) to be passed as command-line arguments. The argparse library is leveraged here for breaking up the command line arguments passed via a shell script. Before we proceed any further, let’s show you that shell script - the pipeline code will make more sense with this in mind.
#run.sh
#executes our pipeline code with all the required arguments
python -m pipeline.pipeline \
--project vanaurum \
--runner DataflowRunner \
--staging_location gs://vanaurum-stock-stream/staging \
--temp_location gs://vanaurum-stock-stream/temp \
--experiments=allow_non_updatable_job parameter\
--input_mode stream \
--input_topic projects/vanaurum/topics/stock-stream \
--output_table vanaurum:vanaurum.stock_stream
About this script:
- This script will be run either locally, or from Google Cloud Shell.
- It will execute your datapipeline using Dataflow as the runner, and provision everything needed behind the scenes.
project: The project you want the resources provisioned under.runner: The runner to use for executing the pipeline. Here we’re using Google Dataflow.staging_location: Required with Google Dataflow - specifies the Google Cloud Storage location where temporary files required for running the pipeline can be stored. Needs to be in the form __gs:///staging temp_locaton: Similar to staging_location. Required by Dataflow as a folder for storing temporary files.experiments: Prevents a known error from arising when Google Dataflow attempts to over-write existing jobs.input_mode: set to stream if your data source is unbounded (which it is, for our stock example)input_topic: The Pub/Sub topic name that input data will be pulled from.output_table: The table in BigQuery where we will output our streaming stock data to.
Now that we have introduced this file, let’s introduce the main script that this will be executing:
#Standard Python Imports
import argparse
import itertools
import logging
import datetime
import time
import base64
import json
#3rd Party Imports
import apache_beam as beam
from apache_beam.io import ReadFromText, WriteToText
from apache_beam.options.pipeline_options import PipelineOptions, SetupOptions, StandardOptions
import six
def parse_json(line):
'''Converts line from PubSub back to dictionary
'''
record = json.loads(line)
return record
def decode_message(line):
'''Decodes the encoded line from Google Pubsub
'''
return base64.urlsafe_b64decode(line)
def run(argv=None):
'''Main method for executing the pipeline operation
'''
parser = argparse.ArgumentParser()
parser.add_argument('--input_mode',
default='stream',
help='Streaming input or file based batch input')
parser.add_argument('--input_topic',
default='projects/vanaurum/topics/stock-stream',
required=True,
help='Topic to pull data from.')
parser.add_argument('--output_table',
required=True,
help=
('Output BigQuery table for results specified as: PROJECT:DATASET.TABLE '
'or DATASET.TABLE.'))
known_args, pipeline_args = parser.parse_known_args(argv)
pipeline_options = PipelineOptions(pipeline_args)
pipeline_options.view_as(SetupOptions).save_main_session = True
if known_args.input_mode == 'stream':
pipeline_options.view_as(StandardOptions).streaming = True
with beam.Pipeline(options=pipeline_options) as p:
price = ( p
| 'ReadInput' >> beam.io.ReadFromPubSub(topic=known_args.input_topic).with_output_types(six.binary_type))
| 'Decode' >> beam.Map(decode_message)
| 'Parse' >> beam.Map(parse_json)
| 'Write to Table' >> beam.io.WriteToBigQuery(
known_args.output_table,
schema=' timestamp:TIMESTAMP, stock_price:FLOAT',
write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND))
if __name__ == '__main__':
logging.getLogger().setLevel(logging.INFO)
run()
Breaking This Script Down
Starting with the run() method:
- This is the main script for running our pipeline
- It accepts
argvas an argument, which is the system arguments passed in ourrun.shbash script that I showed earlier. parser.add_argumentpopulates a known namespace with the options that you pass to it. When you do this, you can use theparser.parse_known_argsmethod to return a two-item tuple of arguments.- Our
pipeline_argsget passed as Pipeline Options for configuring our Pipeline, andknown_argsare going to be used as settings for the rest of our script. - For more information on
argparse, visit the documentation site here. - The last half of this method is our pipeline transformations. Apache Beam has a pattern that works like this:
[Output PCollection] = [Input PCollection] | [Transform]
Or, when applying multiple transformations to the same input:
[Final Output PCollection] = ([Initial Input PCollection] | [First Transform]
| [Second Transform]
| [Third Transform])
In our script, we’re applying each to step to p:
- Read an input
- Decode it using
decode_message() - Parse it using
parse_json() - Write it to BigQuery using the provided specifications.
It’s actually a really simple pipeline.
Ingesting Data From Difference Sources
Note that are data ingestion line here is:
p | 'ReadInput' >> beam.io.ReadFromPubSub(topic=known_args.input_topic).with_output_types(six.binary_type)This a standard I/O pattern for reading from Google PubSub - but there are other standard I/O patterns provided with Apache Beam:
Read from .txt file on Google Cloud Storage
p | 'ReadMyFile' >> beam.io.ReadFromText('gs://some/inputData.txt')Read from in-memory data
p | beam.Create(['Hello, welcome to kevinvecmanis.io',
'this a list contained in-memory',
'that we can read into a PCollection',]))Read from a .csv file
p | 'ReadFromCSV' >> beam.io.ReadFromText('path/to/input-*.csv')Between these I/O types, you should have plenty of options of ingesting data from your source.
Running the Bash Script to Execute the Pipeline
The bash script can be run locally, or from Cloud Shell in your Google Cloud Console. I prefer to clone my files to the home directory in my cloud shell and run things from there.
Either way, when you navigate to your project root and run:
./run.sh
This will execute the pipeline. If you navigate to Dataflow in your Google Cloud Console, you’ll see a diagram of all the transformations steps you specified in your pipeline code. Mine looks like this:
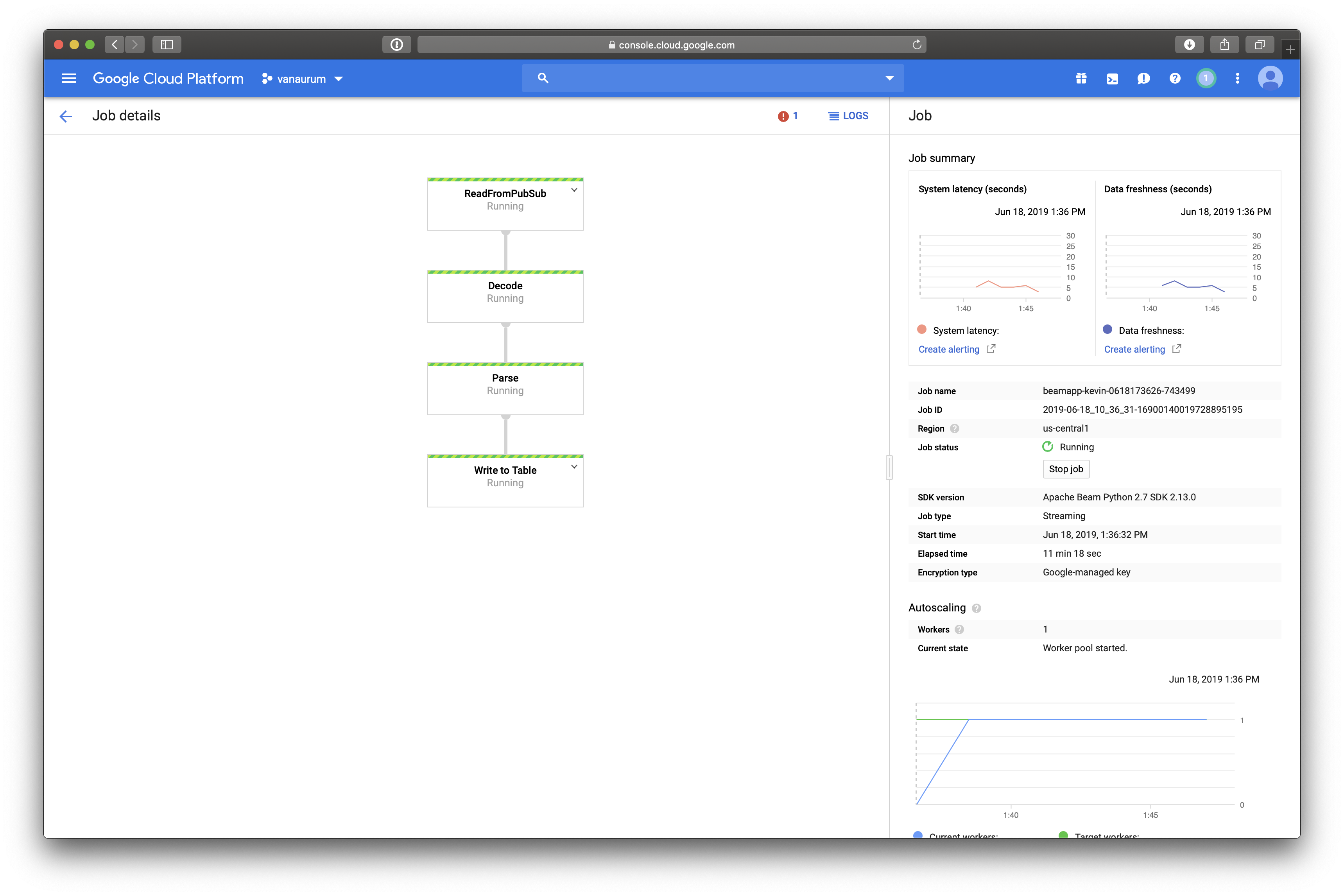
Because the output of our Pipeline is going to Google BigQuery, let’s check there to see if data is appearing in our table:
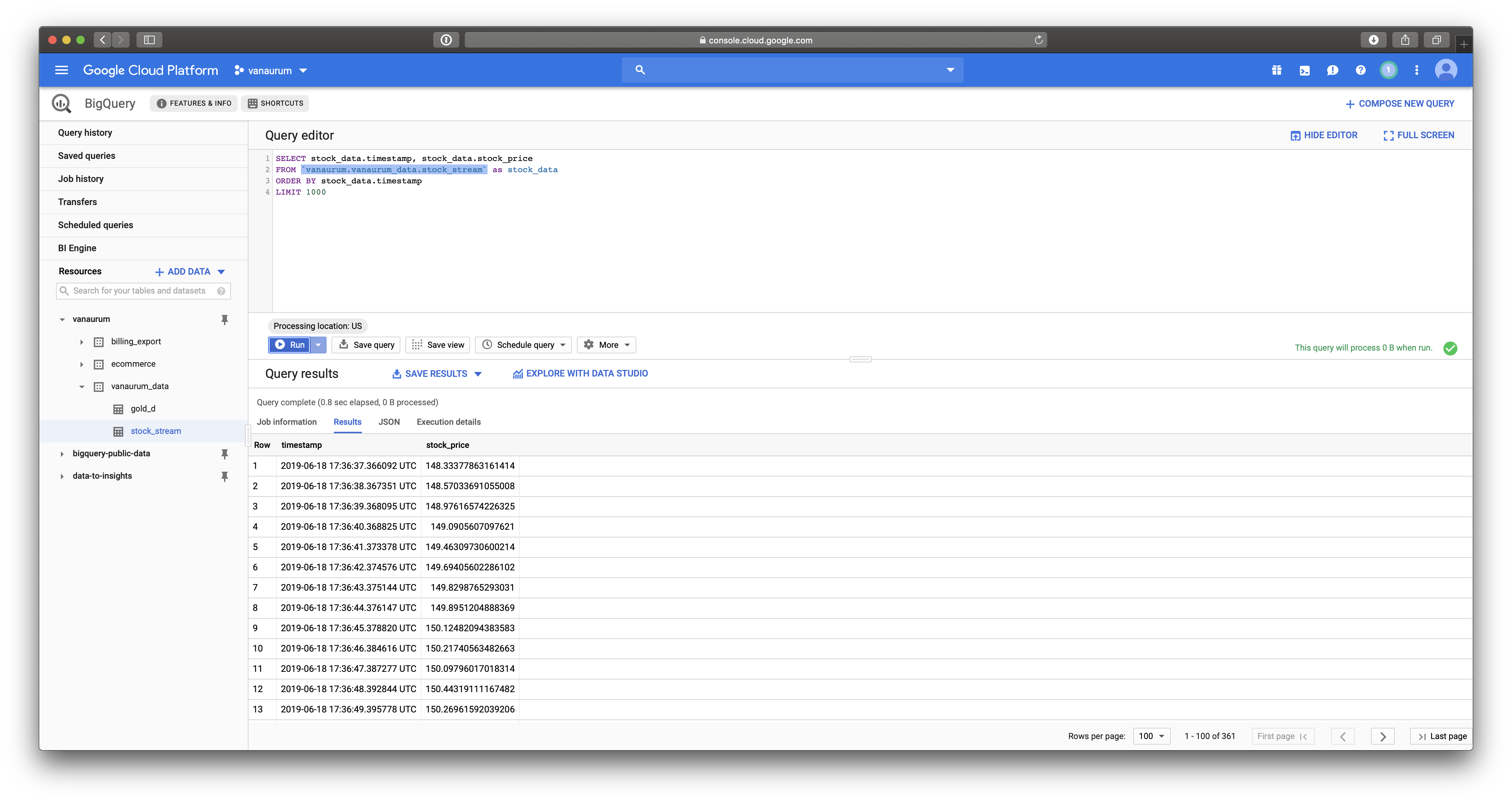
Which it is - great!
Diving Deeper into Apache Beam
The code above is all we really need to execute a simple Apache Beam pipeline that loads streaming data into Big Query. Apache Beam, however, is much more powerful than that. There are some foundational concepts that we glossed over in the code explanation above - I want to discuss those here.
Structural Components of Apache Beam
An Apache Beam pipeline has three main objects:
Pipeline:- A
Pipelineobject encapsulates your entire data processing task. - This includes reading input data, transforming that data, and writing the output data.
- All Apache Beam driver programs (including Google Dataflow) must create a
Pipeline. - When creating the
Pipeline, you also specify the execution steps that tell the runner where and how to run thePipeline.
- A
PCollection:- A
PCollectionis a foundational data structure in aPipeline. - Represents a (potentially) distributed dataset that your Beam pipeline operates on.
- This dataset can be unbounded (streaming data), or bounded (fixed source like a text file).
- Your Pipeline will typically create an initial
PCollectionfrom the input source. From there,PCollectionswill be the input and output to each step of yourPipeline.
- A
PTransform:- A
PTransformis a single data processing operation in each step of yourPipeline. - Every
PTransformtakes one or morePCollectionobjects as an input, processes the data, and produces zero or morePCollectionobjects as an output.
- A
Characteristics of PCollections
- Element Type: The elements within a
PCollectioncan be any type, but they must all be the same type. To support parallel processing, all the elements must be serializable as a byte string. - Immutability: Each
PCollectionis immutable. Once created, elements cannot be added, removed, or changed. When processing is done on aPCollection, it generates new pipeline data but does not consume or modify the original collection. - Element Timestamps: It’s worth noting that each element in a
PCollectionhas an intrinsic timestamp that is assigned by the source that creates thePCollection. It’s important to keep in mind that depending on your application, this timestamp may not be the one you want to use for processing. In our example with the stock price stream, we assigned a timestamp when we published it to Pubsub. This is the timestamp we want to use in any windowing or processing steps for the stock data. Also keep in mind that the intrinsic timestamp assigned by the source creating thePCollectionmight be significantly different than any timestamp embedded in the source dataitself.
Characteristics of PTransforms
- Transforms are operations that are applied on your pipeline.
- Typically, the user provides processing logic in the form of a function object - examples of these above are
parse_jsonanddecode_message. - To harness the true power of Apache Beam, processing functions should leverage the parallel processing capabilities of Beam by sublassing built in parallel processing classes in Beam, like
ParDo. - Apache Beam specifies requirements for writing these functions here.
- The key requirement is that the functions need to be serializable so that they can be sent over the wire to other computing nodes for execution. This has some implications on its own:
- The function should be stateless.
- The function should be as simple as possible.
- The function should avoid complex nested logic and recursive calls if possible (to avoid complications with serialization).
- The function should avoid the use of global variables.
- What is serialization? It’s just the conversion of a function into a byte string so that it can be transmitted over wire.
Serializing / Deserializing a function
>>> import pickle
>>> def add_one(n):
... return n+1
... ser = pickle.dumps(add_one)
>>> ser
b'\x80\x03c__main__\nadd_one\nq\x00.'
>>> add_one = pickle.loads(ser)
>>> add_one(5)
6
This is what they mean when they say the function needs to be serializable.
Summary
- In this post I walked through how to send streaming data to a table in Google Big Query.
- We went over some of the structural foundations of Apache Beam and how all the pieces fit together.
- I showed several ways of reading data into Apache Beam Pipelines.
- We finished by doing a deeper dive into Pipelines, PCollections, and a PTransforms.
I hope you enjoyed this post!